AAAI 2023实用AI挑战赛冠军方案分享
2023年1月,AAAI 2023 实用AI挑战赛落下帷幕。我所在的team_kppkkp队获得总榜冠军。在此,分享一下我们队本次比赛的方案,抛砖引玉。
本次比赛由商汤科技联合北航刘祥龙教授团队,携手安徽合肥数据空间研究院、天数智芯、科大讯飞、OpenI 启智新一代人工智能开源开放平台等机构与企业,在国际顶级人工智能会议AAAI 2023上举办,旨在搭建一座连通学术与工业化落地的桥梁,筛选出效果好、效率高、鲁棒性强的模型设计,推动人工智能领域朝实用方向发展。

比赛网址 https://practical-dl.sensecore.cn/
1. 赛题描述
本次比赛针对交通灯和交通标志识别任务,参赛队伍需要充分考虑硬件特性,在不同算力、算子支持和模型量化方案的7个指定硬件平台,设计出在各个平台表现最优异的模型,或者多平台通用的“全能”模型。模型得分由精度得分和速度得分共同决定。
比赛涉及的硬件平台包括:
- 安防芯片:华为Atlas 300 / 瑞芯微 RV1126
- 云端GPU芯片:英伟达 Tesla T4
- 手机芯片:高通SNPE GPU、DSP
- 自动驾驶芯片:德州仪器TDA4VM
- 商汤自研推理芯片:商汤STPU S1
2. 方案分享
2.1 Baseline模型选择
团队分别测试了ResNet、MobileNet、RegNetX、RegNetY 等主流模型。其中,MobileNet 和 RegNet 中使用了组卷积以减少计算量,RegNetY中使用了SqueezeExcitation (SE)模块以提升准确率,但由于内存访问量(MAC)较大、平台对算子优化不够等原因,这些部件在多个平台上推理速度不理想。综合考虑精度、速度和提升潜力,最终选取了ResNet-18-0.25作为baseline,并在其基础上进一步对模型结构调优,以达到更快的推理速度。
损失函数使用 Equalization loss (Eql),以增强长尾分布下目标分类的性能。
2.2 数据增强
为增强模型泛化性,团队采用翻转 (p=0.5)、缩放裁剪 (p=0.9)、仿射变换作为几何上的数据增强,采用边缘填充(maxratio=0.2)、添加高斯噪声(p=0.15)、颜色抖动、高斯模糊(p=0.15)作为色彩上的数据增强。
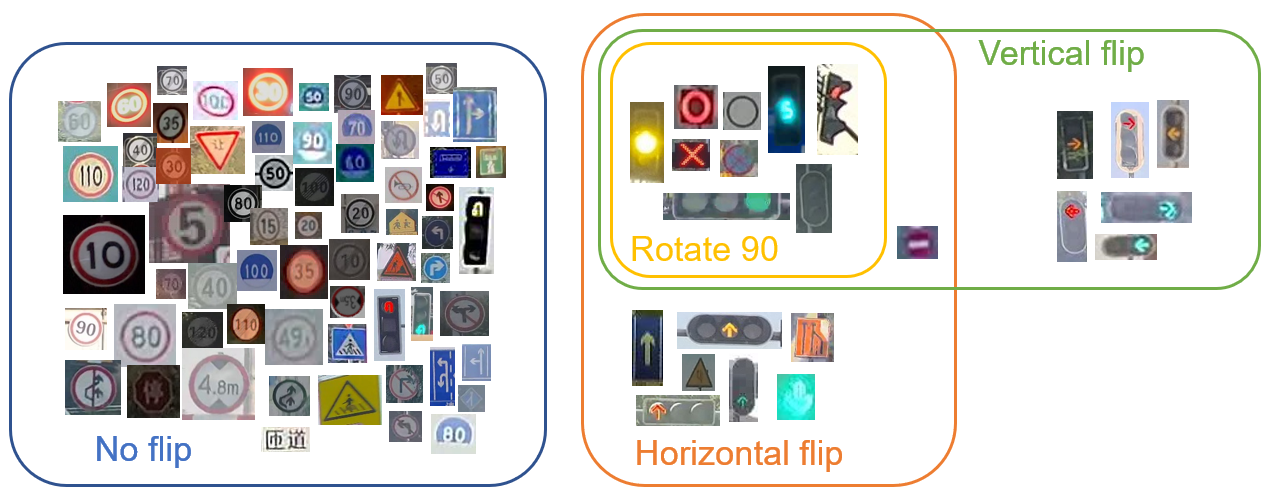
特别的,对于翻转,团队设计了类相关的翻转,所有89个类别对应的翻转方式如图1所示。该策略与不使用翻转相比,精度提升1.2,与所有类别都翻转相比,精度提升6.2。
对于缩放裁剪 random_resized_crop_wh_filter,使用参数 scale=[0.8, 1], ratio=[0.7, 1.3],以避免极端长宽比的图片因裁剪而丢失有效信息,如图2所示。与默认参数相比,该修改使精度提升1.1。

对于其他数据增强,与不使用相比,精度提升0.2。
此外,数据集存在严重的长尾分布问题,各类别的样本数最高可达5121,而最低仅有8。经过统计分析,我们将样本数不满100的类别使用数据增强扩充到100,这一操作带来0.4的精度提升。
2.3 算子调整
ResNet 中的 shortcut 可以看作是一种多分支结构,多分支结构可以带来精度提升,这一点在 InceptionV3 论文中也有体现。但是在推理时,多分支结构会造成一定的延迟。论文RepVGG通过结构重参数化技巧,将多分支模型等价转换为单路模型,使得模型训练和部署时采用不同结构,既可以受益于多分支结构的精度提升,又实现了部署时单路架构推理。
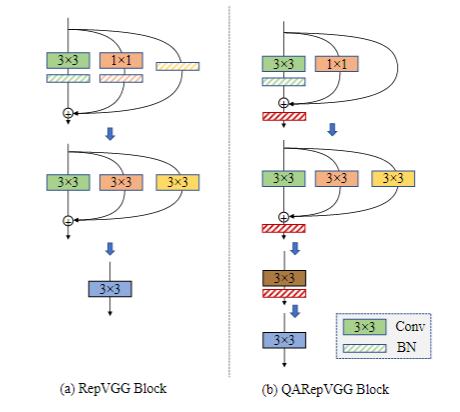
但是团队实践中发现,RepVGG 量化后掉点严重。论文 QARepVGG提出了一种对量化友好模块,降低了量化后的精度下降。模块结构如图3所示,分别为 3x3 卷积-BN 分支,identity 分支和 1x1 卷积分支,三者相加后经过一个 BN 层。推理时,首先将 3x3 卷积和 BN 层融合,接着将 identity 和 1x1 卷积等价转换为 3x3 卷积。1x1 卷积可以转换为只有中心处有非零值的 3x3 卷积,identity 分支可以转换成类似单位矩阵的 3x3 卷积。最后将三个 3x3 卷积相加,与最外层 BN 层融合,得到转换后的单个卷积核。
在比赛中,团队将baseline中所有的多分支结构替换为了 QARepVGG Block。与baseline相比,此操作能有更快的推理速度;与多分支结构直接替换为普通卷积相比,QARepVGG能在多数平台有更小的精度损失。
2.4 输入尺寸与模型结构调整
为了进一步加快推理速度,团队减小了输入尺寸,并对应裁剪了网络。团队总结的裁剪原则如下:
- 只使用 3x3 的卷积和直筒型结构,不使用其他卷积,因为 3×3 卷积核在设备中优化的比较好。
- 使用卷积的 stride=2 进行下采样,而不是额外增加 pooling 层。减少额外网络层带来的时间消耗,且部分平台如高通 698dsp 对池化计算较慢。
- 减小输入尺寸后,需要降低模型的下采样率,适当增加通道数,对下采样操作的位置进行设计,以减少精度损失。
- 用宽通道卷积代替多个窄卷积,以缓解推理速度的访存瓶颈。
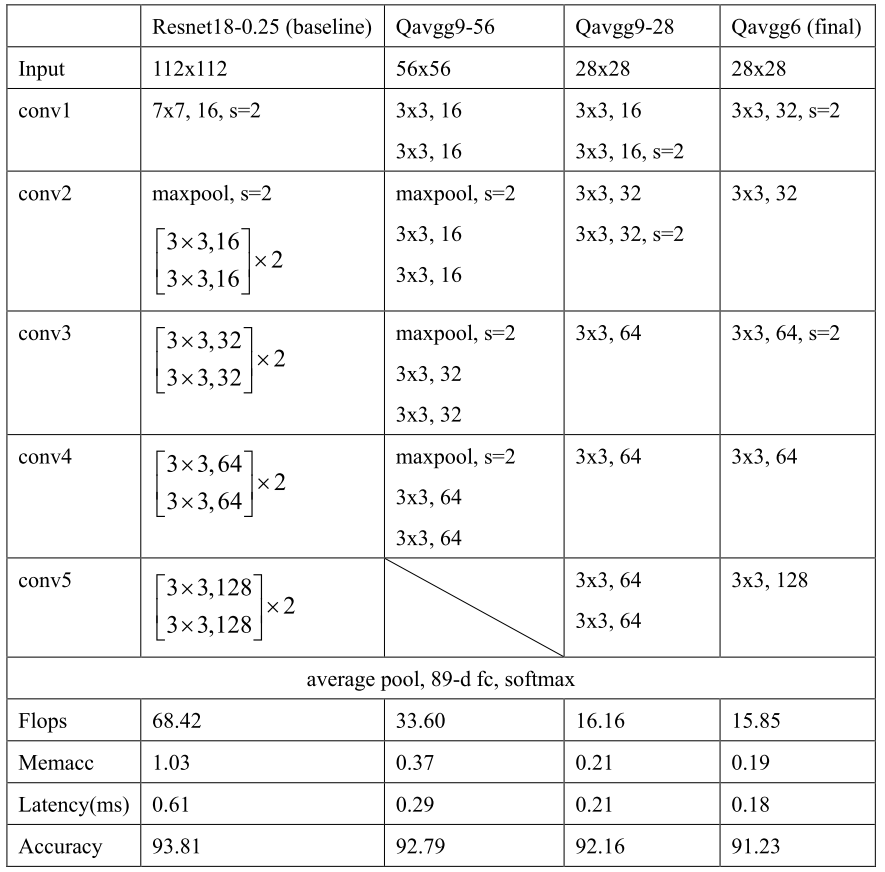
团队设计的部分模型以及最终模型的结构及性能对比(以STPU平台为例)如下表。比赛结果表明,团队根据以上经验设计的模型与NAS搜索得到的模型基本吻合甚至更优。
比赛代码已开源:https://github.com/LingyvKong/UP-AAAI2023challenge-1st.git


NB