DETR系列算法
Detection Transformer 是从2020年开始的一种全新的端到端的目标检测范式,图片通过CNN提取特征,然后将提取的特征展平输入transformer encoder-decoder,然后通过一系列查询,检测头输出每个查询的结果。查询的数量通常为100、300或900,远远少于之前的检测算法中的密集预测。
1. DETR
DETR: End-to-End Object Detection with Transformers (ECCV 2020)
整个算法的流程是:Backbone&Neck -> 位置编码 -> Encoder -> Decoder -> FFN -> 匹配机制和loss计算。
其中,backbone用于提取特征,通常用resnet或swin,以Resnet50为例,它有5个阶段的输出,DETR只用了最后一层C5的输出,shape为[bs, 2048, h/32, w/32],因此对小目标精度不友好,后续的Deformable DETR有针对这点进行改进。backbone部分的学习率是其他部分的0.1倍。由于后续transformer的输入是256的,所以backbone的特征再过一层1*1的卷积,得到shape [bs, 256, h/32, w/32]。
transformer的输入是序列化的,因此将特征展平变为 [bs, n, c], n=h/32 * w/32,当batchsize大于1且不同图像尺寸不同时,要padding到同一尺寸。之后加上位置编码,前128维为行编码,后128维为列编码。
Encoder和Decoder的结构如图所示:
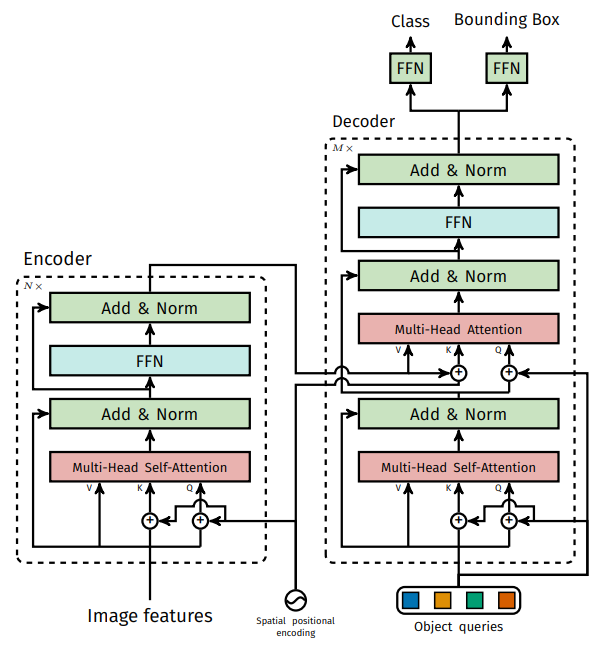
Encoder由6个Encoder_layer串联组成,每个Encoder_layer都会加上位置编码,这点不同于NLP只在最开始加一次位置编码。多头注意力中各个头的线性层的参数是共享的,Encoder输出shape与输入相同。
Decoder由6个Decoder_layer串联组成,Decoder_layer由Self-attention和Cross-attention组成,Self-attention的输入需要query和query_pos,query初始设为零向量,会在Decoder_layer逐层更新,每个query用于一个目标的位置和类别的预测。query_pos是query的位置嵌入,在所有Decoder_layer是一样的,设置为100个可学习的向量 nn.Embedding(100,256)。object queries通俗解释就是,训练N个人,每个人对不同的事物感兴趣,包括不同的类别信息和不同的区域,然后这些人都将输出他们感兴趣的内容的最佳预测。由于transformer的decoder端也有self-attention,因此各个位置之间可以互相通信和协作。研究表明,Self-attention在DETR结构中必不可少。object queries代替了传统检测中anchor的作用,但是设计地很妙,像人类分辨时的方式,判断一个物体时只关注这个物体所在的区域范围。即这里用query做attention。6个Decoder_layer的输出都会过一个共享的FFN得到预测类别和位置结果,然后参与loss的计算,这是深监督。采用匈牙利匹配进行label Asign,定位损失为L1 loss和GIoU loss,分类损失为交叉熵损失。
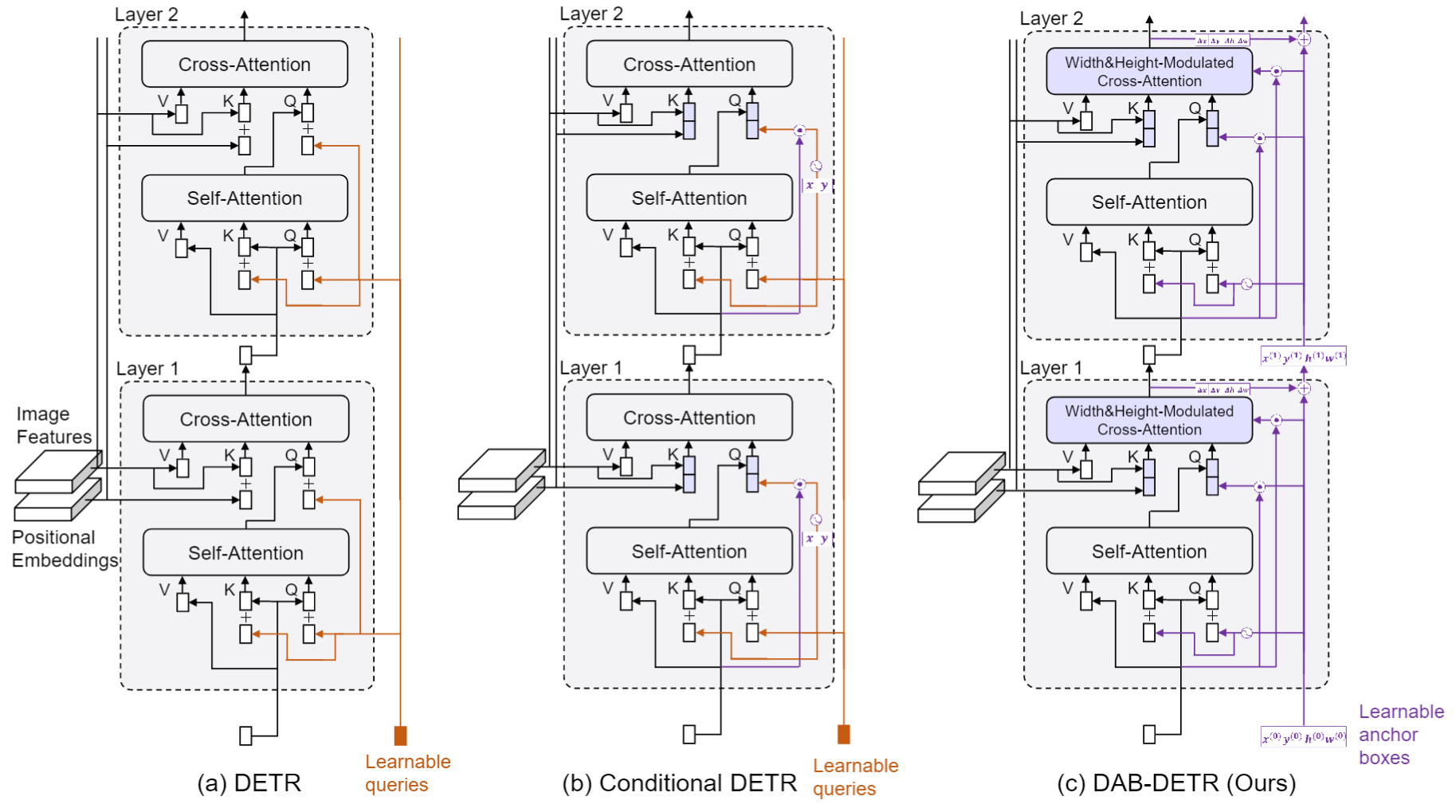
2. Conditional DETR
Conditional DETR (ICCV 2021) 针对DETR收敛慢的问题,增加query的数量从100到300,分类损失改为Focal loss。此外,核心贡献是提出了Conditional Attention,解耦了内容attention和位置attention,避免pos和content的混淆,实现方法是将self-attention和cross-attention的输入进行修改,原先是query和query_pos相加后输入attention结构的线性层,修改为query和query_pos各自经过不同的线性层,然后将结果concate。此外,位置预测由DETR的全局位置改为预测相对位置,query_pos经过线性层压缩为2维,类比anchor point。
Anchor DETR 进一步将原本Decoder的 query_pos 直接变为了2维,不需要线性层,直接代表参考点。
DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR (ICLR 2022) 在位置编码增加了对hw的编码,4者编码concate得到256*2维的编码。在query_pos也同样增加hw的编码,类比anchor box。并且提出Box Refine,如下图所示,每个Decoder_layer的输出里增加了对参考框的修正$\Delta x, \Delta y, \Delta w, \Delta h$,这样,输入每个Decoder_layer的参考框就越来越精确。另外,参考框的梯度反向传播被detach,让每个Decoder_layer的优化相对独立,使优化效果更好。参考框还被用于cross_attention中的attention调制。
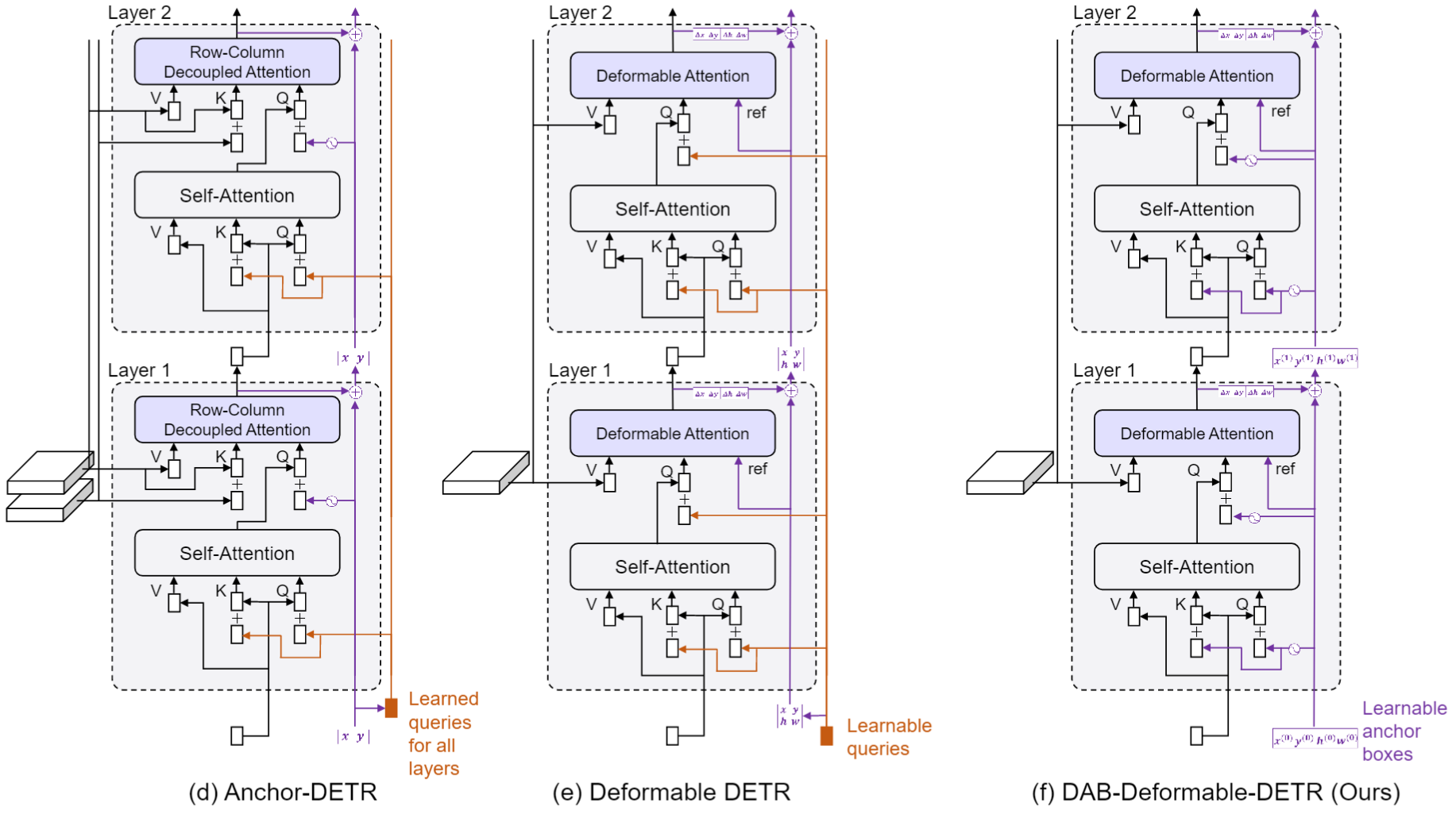
3. Deformable DETR
Deformable DETR (ICLR 2021)提出了多尺度可变形注意力(Multi-scale Deformable Attention, MSDA)用于替代Encoder的Self-attention和Decoder中的Cross-attention,基于此设计了DETR利用多尺度特征检测的流程,不仅使DETR拥有了多尺度优势还减少了计算量。此外,它还提出了两阶段DETR的思路,利用编码器输出特征来初始化解码器的query及其对应的位置。该方法的思想对后续研究有很大的指导意义。MSDA的计算方法如下,注意这里的公式描述的角度是单个query的输出:
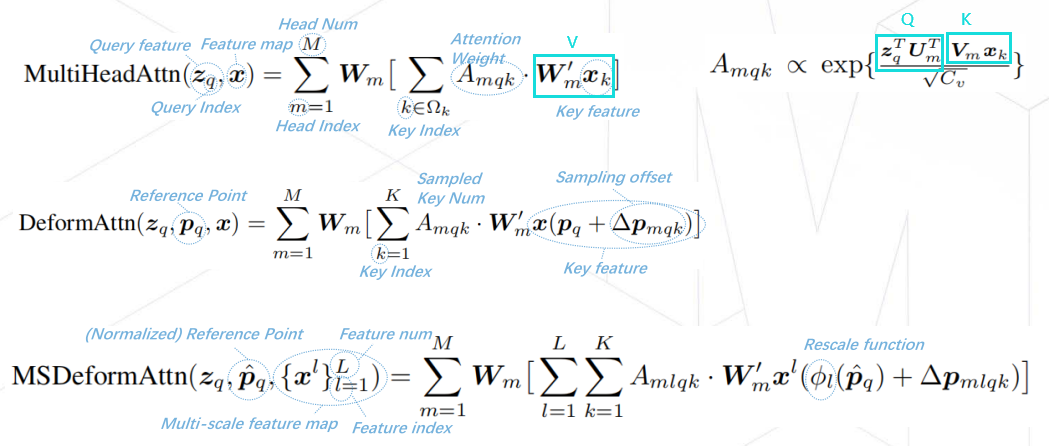
看DeformAttn公式,Reference Point是给定的参考点,即query特征所在位置的归一化坐标,模型需要自己去找K个采样点来计算attention,示意图如下,可以与公式对应。
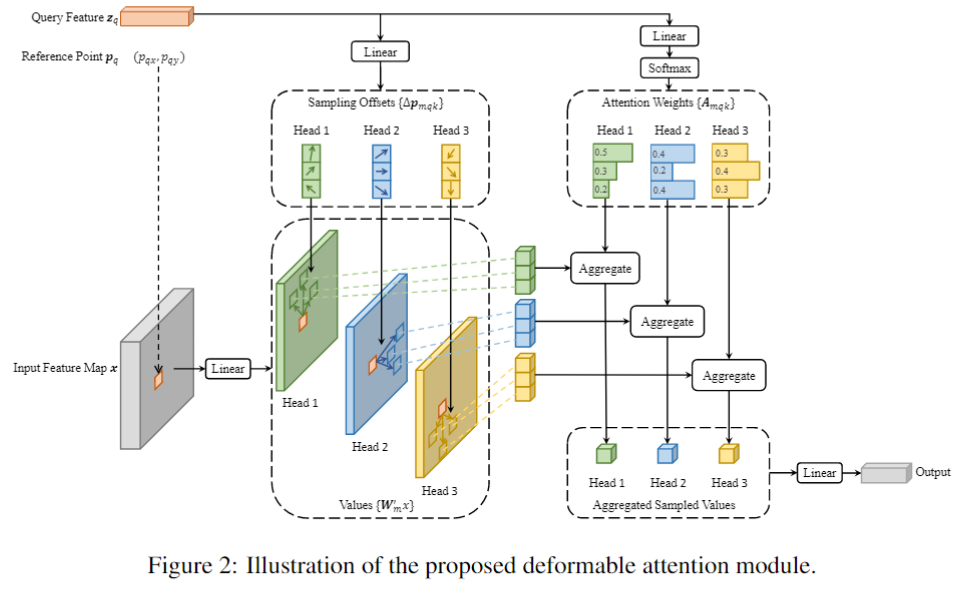
多尺度的DeformAttn就是采样不需要局限在一个尺度,而是各个尺度都可以采样,实现跨尺度的特征交互。
Deformable DETR提出的两阶段DETR是把Encoder得到的特征过一个class embed,选取topK个作为参考点。
4. DINO
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection (ICLR 2023) 基于DAB-Deformable-DETR(Deformable-DETR++ box refine & two stage),DINO设计了非常有效的训练模式:Denoising(最早在 DN-DETR 提出),本文改进了DN(Contrastive DeNoising, CDN),此外,调整了query/reference 初始化的方式、box detach 等多处细节。DINO的框架如下图所示:

在详细介绍DINO之前,先介绍一下什么是DeNoising,DN不改变模型参数、结构、具体计算方式,是一个仅用于训练时期的辅助任务,主要为了获取loss,DN 具有极强的拓展性,可以用在各种 DETR,甚至可以用在 RCNN系列算法上。它的想法是既然DETR的Decoder部分是从不精确的proposal慢慢变为预测框的过程,那就可以设计方法给gt加噪声,想办法编码成decoder输入,用带噪声的gt box作为proposal,训练decoder去噪,用decoder输出和gt算loss,为了加速训练,可以多次DN,形成多个group。而CDN则是为DN增加了对负样本的去噪训练。
在CDN中,group 数量根据 gt 数量动态决定,防止某张图中gt框过多爆显存。每个 group 一半正样本一半负样本,正样本计算 box & label 重建损失,负样本 gt 设为 no obj. 类,只计算 label 损失,在 batchsize > 1 时,会用补零补齐目标数少的样本。在生成DN label query时,随机选 0.5*noise_scale作为噪声标签,选出来的这些用随机的目标类别标签覆盖原来的标签,因此,实际噪声比例小于 0.5 * label_noise_scale,与 num_classes 有关。在不同类别数的数据集可能要调整参数,如果原代码数据集用的是coco,是80类,你自己的数据只有4或4个类,需要适当加大noise_scale参数。在生成DN bbox query时,是对bbox左上角和右下角的点进行加噪挪动,也有一个scale参数控制挪动的范围。对于DN mask,各个 group 应当能看到组内的信息,但看不到其他组的信息,matching part 不应当看到 denoising groups 的信息,因为其蕴含 gt 的信息。

