SAM 好比在视网膜层面,能力是很low-level的,举个例子它可以对图片信息进行简单的切分,但它不知道左边的一坨像素和右边的一坨像素是一个品种的狗。DINOv2好比大脑中某块视觉区,好比刚出生不久的婴儿,它是纯视觉的,可以完成视觉层面的目标聚类,知道左边的一坨像素和右边的一坨像素是一种东西,但没有语言系统不知道这种东西叫“金毛犬”。CLIP就是更近一步,实现了视觉和语言的关联,好比5岁的小孩;然而由于数据、训练方式、输入分辨率等原因,CLIP没正经读过书看过图表,所以在做dense OCR任务时Vary自己训了个encoder,在做chart任务时Onechart也自己训了个encoder,好比让小孩上个学。🐶
Vision encoders百花齐放,与decoders相匹配。当decoder是LLM时,需要LLM能看懂的encoder。
Vision-Language 的 Vision Encoders
1. CLIP 2021.2.26
论文:Learning Transferable Visual Models From Natural Language Supervision(OpenAI in ICML2021)
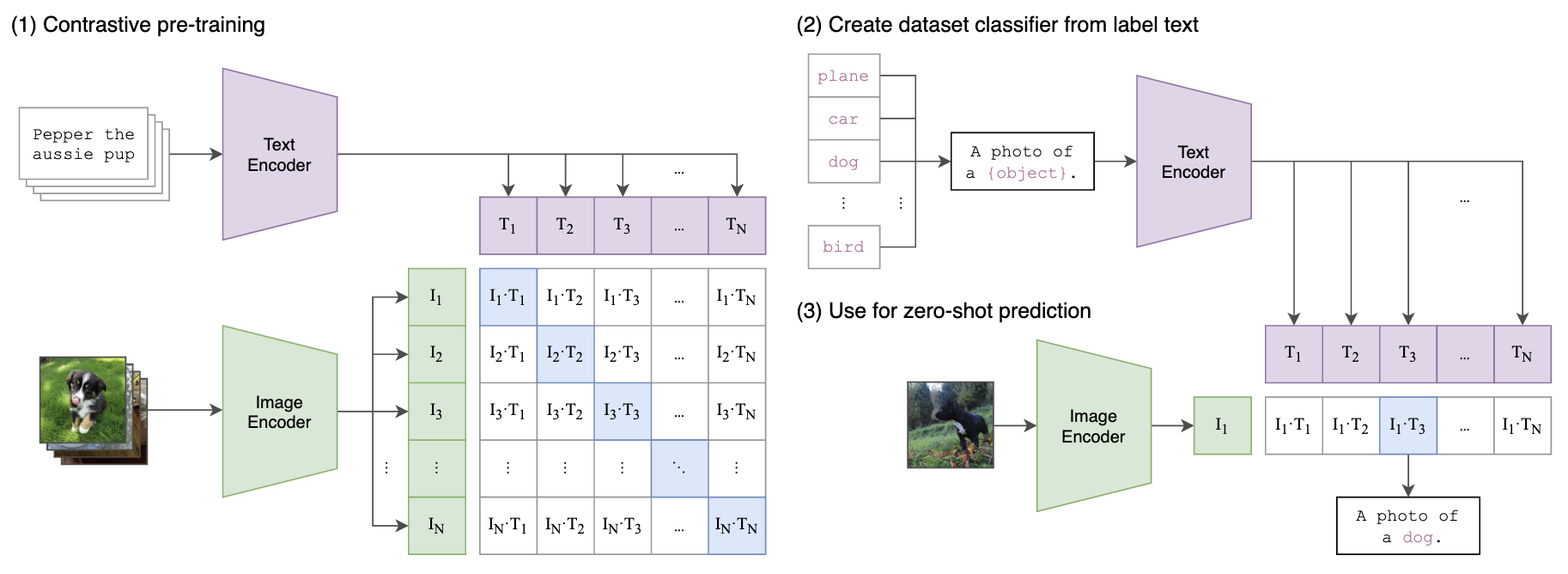
如下图所示,将图片和文本描述通过网络都得到768维的Embedding,其中文本编码器使用transformer,图片编码器使用了ResNet和ViT两种结构进行实验,ViT的有4个模型:输入224px 的 ViT-B/32, ViT-B/16 (196 tokens), ViT-L/14 (256 tokens);输入336px的 ViT-L/14 (576 tokens)。预训练使用了400M(4亿)个图像文本对,每个batch采样三万多个这样的配对,通过对比学习,配对的Embedding位置处为1,非配对处为0进行交叉熵损失训练。
在测试时支持zero-shot推理,如下面右图所示:首先分别获得图像和文本的embedding,对提取的embedding进行归一化用来算相似度image_features /= image_features.norm(dim=-1, keepdim=True), text_features /= text_features.norm(dim=-1, keepdim=True)。通过计算图片Embedding和各个候选("a photo of [cls_name]")的相似度,相似度大于某个阈值或者topk的为输出类别结果。
- 阅读剩余部分 -