Vision Encoders in VLM
SAM 好比在视网膜层面,能力是很low-level的,举个例子它可以对图片信息进行简单的切分,但它不知道左边的一坨像素和右边的一坨像素是一个品种的狗。DINOv2好比大脑中某块视觉区,好比刚出生不久的婴儿,它是纯视觉的,可以完成视觉层面的目标聚类,知道左边的一坨像素和右边的一坨像素是一种东西,但没有语言系统不知道这种东西叫“金毛犬”。CLIP就是更近一步,实现了视觉和语言的关联,好比5岁的小孩;然而由于数据、训练方式、输入分辨率等原因,CLIP没正经读过书看过图表,所以在做dense OCR任务时Vary自己训了个encoder,在做chart任务时Onechart也自己训了个encoder,好比让小孩上个学。🐶
Vision encoders百花齐放,与decoders相匹配。当decoder是LLM时,需要LLM能看懂的encoder。
Vision-Language 的 Vision Encoders
1. CLIP 2021.2.26
论文:Learning Transferable Visual Models From Natural Language Supervision(OpenAI in ICML2021)
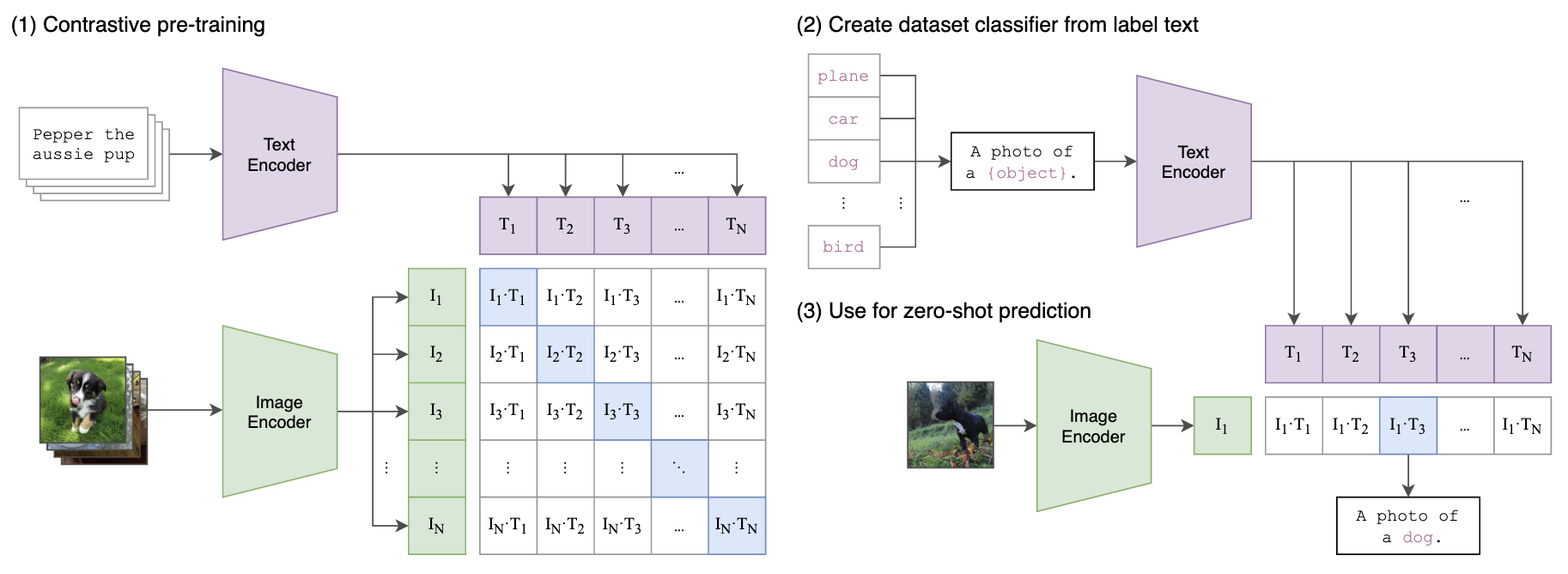
如下图所示,将图片和文本描述通过网络都得到768维的Embedding,其中文本编码器使用transformer,图片编码器使用了ResNet和ViT两种结构进行实验,ViT的有4个模型:输入224px 的 ViT-B/32, ViT-B/16 (196 tokens), ViT-L/14 (256 tokens);输入336px的 ViT-L/14 (576 tokens)。预训练使用了400M(4亿)个图像文本对,每个batch采样三万多个这样的配对,通过对比学习,配对的Embedding位置处为1,非配对处为0进行交叉熵损失训练。
在测试时支持zero-shot推理,如下面右图所示:首先分别获得图像和文本的embedding,对提取的embedding进行归一化用来算相似度image_features /= image_features.norm(dim=-1, keepdim=True), text_features /= text_features.norm(dim=-1, keepdim=True)。通过计算图片Embedding和各个候选("a photo of [cls_name]")的相似度,相似度大于某个阈值或者topk的为输出类别结果。
2. OpenCLIP 2022.9 (Stability AI)
由于CLIP没有开源数据,2022年9月LAION发布OpenCLIP,用1~2B数据训了不同规模的CLIP模型,在ImageNet Zero-shot Acc上优于原CLIP,如 224px输入的有:ViT-B/32, ViT-B/16, ViT-L/14, ViT-H/14, 和ViT-g/14。
总结,CLIP有如下版本,这些版本只有数据差别,或模型尺寸差别:
- CLIP:OpenAI原版,只开放了权重。有224px的B/32, B/16, L/14;和336px的 L/14
- OpenCLIP:第一个全开源的CLIP复现,开源了代码、数据、模型
- MetaCLIP:处理数据时加了子字符串匹配和数据分布平衡,他们的数据训出来的CLIP在ImageNet zero-shot acc略好于DataComp-1B训的。
- EVA-CLIP:BAAI提出,用了2B数据训练,除常规尺寸外还提供了超大的CLIP模型 EVA-CLIP-18B
- DFN CLIP:Apple提出,从43B数据中过滤出了5B的数据训练。有224px的B/16, L/14, H/14 和378px的 H/14
3. FLIP 2022.12
论文:Scaling Language-Image Pre-training via Masking
在后续的改进中,Kaiming团队的FLIP证明,对图片进行50%的mask后只对非mask部分计算Embedding来训练CLIP,只在最后几轮用unmask训不会降低CLIP的性能,反而可以起到一定的正则化作用。他们也尝试了增加MAE loss,但没有带来性能提升。
4. SigLip 2023.3
论文:Sigmoid Loss for Language Image Pre-Training (Google)
SigLIP 提出把 CLIP 中的loss function 变为 a simple pairwise sigmoid loss. 由于不需要softmax,只需要过sigmoid,所以SigLIP可以支持更大的batchsize(虽然实验结果表明 32k的batchsize就足够了)。模型实现了84.5% ImageNet zero-shot accuracy,优于CLIP、OpenCLIP、EVA-CLIP。
CLIP: batch内的图文对做多分类softmax;比如下图第一行表示第一个文本与batch内哪个图片匹配,除了行还计算列,比如第一列表示第一个图片与哪个文本匹配。
SigLIP: batch内的图文对做二分类sigmoid,比如下图第一行表示第一个文本分别与batch内每个图片做二分类。

loss伪代码实现如下:
I_f = image_encoder(I) # [n, d_i]
T_f = text_encoder(T) # [n, d_t]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1) # [n, d_e]
T_e = l2_normalize(np.dot(T_f, W_t), axis=1) # [n, d_e]
# CLIP
logits = np.dot(I_e, T_e.T) * np.exp(t) # t is learned temperature parameter
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
# SigLIP
logits = np.dot(I_e, T_e.T) * np.exp(t) + b # t, b is learned temperature and bias
labels = 2 * eye(n) - ones(n) # -1 with diagonal 1
loss = -sum(log_sigmoid(labels * logits)) / n5. MoDE 2024.4
论文:MoDE: CLIP Data Experts via Clustering(Meta in CVPR2024)
这篇文章的思想如下图所示,由于一张图的caption可能是多个维度的,CLIP把所有的caption混在一起学容易引入false negative。MoDE提出了数据专家的概念,每个数据专家学习一种类型的caption。具体做法是:首先把训练的image-text pair数据根据caption聚类成几个不相交的子集,每个子集训一个CLIP(Data Expert)。在推理时,首先计算推理的text和哪个聚类中心接近,就用哪个CLIP给出预测结果。
MoDE可以在分类任务、image-text检索、text-image检索任务上比OpenCLIP高约3个点。而且多个expert可以异步同时训练。并且有利于后期随时增加expert。

6. NaViT 2023.7
论文:Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution (Google DeepMind)
支持任意分辨率输入的vision tokenize。
其他Vision Encoders
1. SAM 2023.4
论文:Segment Anything (Meta)
模型结构是ViTdet,输入$1024 \times 1024$。
2. TAP 2023.12
论文:Tokenize Anything via Prompting (BAAI)
在SAM的基础上,可以对分割出的部分做classify、caption任务。个人感觉这里的encoder可以抽出来用在VLM。
3. DINOv2 2023.4
论文:DINOv2: Learning Robust Visual Features without Supervision (Meta)
模型是纯视觉自监督预训练的,是DINO的升级,结合了DINO和iBOT的损失函数,以及SwAV的中心化技术,DINO名字含义是 self-DIstillation with NO labels。
1.Image-level objective (图像级目标DINO)

采用学生-老师自蒸馏训练方法,学生和教师采用完全相同的结构,学生模型通过反向传播更新,教师模型采用指数移动平均方法(EMA)更新参数,即 $\theta_t \leftarrow \lambda \theta_t + (1-\lambda)\theta_s$ ,最终目的是得到学生模型。其基本思想是将输入图像 $x$ 经过不同的数据增强和采样策略后得到 $x_t, x_s$ 分别送给教师和学生,利用教师和学生输出表征 (cls token 对应的向量) 的交叉熵来学习提取图像全局特征的能力。
DINO 中最核心的数据采样策略便是图像裁剪,这也是自监督学习领域应用非常广泛的主策略之一。一般来说,我们可以将裁剪后的图像分为两种:
- Global views: 即全局视角,也称为 large crops,指的是抠图面积大于原始图像的 50%;
- Local views: 即局部视角,也称为 small crops,指的是抠图面积小于原始图像的 50%;
在 DINO 中,学生模型接收所有预处理过的 crops 图,而教师模型仅接收来自 global views 的裁剪图。这是为了鼓励从局部到全局的响应,从而训练学生模型从一个小的裁剪画面中推断出更广泛的上下文信息。此外,为了使网络更加鲁邦,DINO 中也采用一些其它的随机增强,包括:颜色扰动(color jittering),高斯模糊(Gaussian blur),曝光增强(solarization)。
参考:
重塑自监督学习: DINO 网络如何颠覆视觉特征表示的常规方法
自监督视觉transformer模型DINO
2.Patch-level objective (Patch级目标iBOT)

采用学生-老师模型训练方法,采用了指数移动平均方法(EMA)更新老师模型的参数。教师拥有全部图像信息,而学生的图像随机遮挡一部分patch,通过降低分类损失$L_{\text{[CLS]}}$和重建mask部分的损失$L_{\text{MIM}}$,从而训练学生网络。
两种目标采用不同的head。因为实验发现,当两个级别的损失函数共享同样的参数时,模型在Patch级别会欠拟合,在图像级别会过拟合。
训练数据为本文提出的LVD-142M,它是由公开数据(干净数据curated data,包括分类、检索、分割、深度估计的数据集)和网络数据(uncurated data)组成的,数据清洗构建pipeline如下图:


