🎁 VLM 常用的训练 Dataset
本文对VLM领域的常见数据集做了简要介绍和分类,以方便读友看论文时参考。
本博文将部分数据划分为了粗加工、精加工、套餐数据。其中粗加工一般指数据中的video是作者首次收集的,但由于提出时间较早,当时提供的caption比较简单或粗糙。很多“粗加工”数据中的videos被新的工作使用并提供了更好的caption,被称为“精加工”数据。“套餐数据”则是进一步包含了多个精加工数据。
注意:本文信息仍在时常更新中...
图文数据
1.image-text pair 数据
粗加工
LAION2B:LAION5B数据集是从网页数据Common Crawl中筛选出来的图像-文本对数据集,它包含5.85B的图像-文本对,其中文本为英文的数据量为2.32B,这就是LAION2B数据集,它是LAION5B的英文子集。著名的stable diffusion generative model训练集就包括了LAION5B。
LAION-400M:下载原图和文本对的话,大概有10T左右。LAION-400M提供了400M数量的图文对,以及他们的CLIP embedding和kNN索引,因此可以对这个大数据集高效索引。索引网站:https://rom1504.github.io/clip-retrieval/
LAION-400M在收集数据时,做了一些过滤设定:
- 将文本短于5个字母或者图像小于5kb的图文对丢弃;
- 去重操作;
- 用CLIP计算图文相似性,抛弃掉相似性低于0.3的图文对;(很重要)
- 筛除一些不合法的图文对,比如adult/violence/insulting等等。(love and peace化)
LAION COCO: 对LAION2B中的600M 个图片,使用 BLIP L/14 and 2 CLIP versions (L/14 and RN50x64)打了COCO风格的captions标注。数据官网:LAION COCO
DataComp-1B:Apple公司训练他们的CLIP使用的数据。
TaiSu(太素): 中文视觉语言预训练数据集,数据量 166M。数据官网:TaiSu
COYO:由于伴随的文本取自Alt-text,COYO的文本通常很短。
精加工
等着吃现成的吧hhh
LAION-GPT-4V:12.4k,LLaVA-1.6用了此数据。
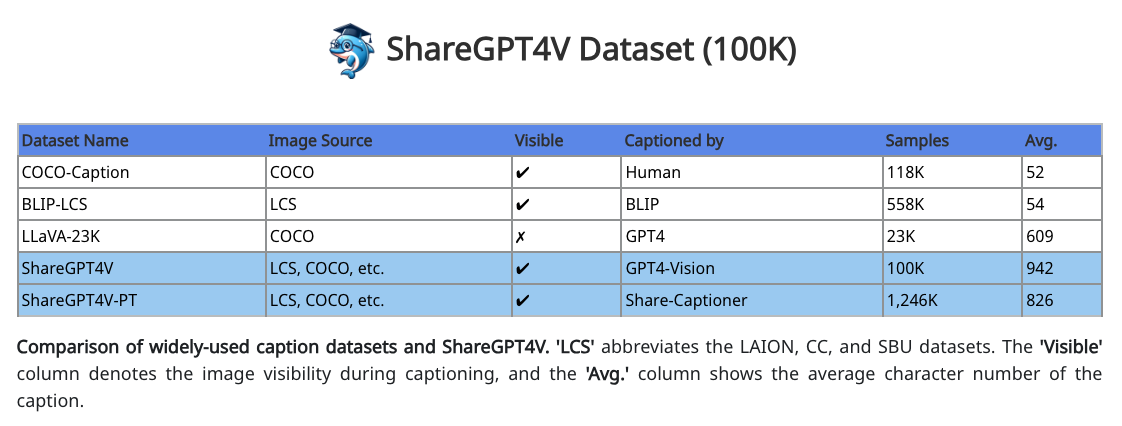
ShareGPT4V: 100k个GPT4V生成的caption图文对,基于这数据训了个caption模型并开源,并给了1.2M个他们模型生成的高质量caption图文对。LLaVA-1.6用了此数据。
DenseFusion (2024.7, NIPS 2024): BAAI提出,Emu3使用了该数据,开源了 DenseFusion-4V-100K and DenseFusion-1M。 1M 图片来源select 1M highly representative images from uncurated LAION dataset through Semantic Clustering and De-duplication.
2.interleave数据
在论文VILA: On Pre-training for Visual Language Models中指出,pretrain阶段需要加interleave数据。最好是interleave和pair都用。
SFT阶段需要加text数据,可以把pretrain阶段 MMLU 的掉点救回来。
| Dataset | Type | Text Src. | #img/sample | #tok./img |
|---|---|---|---|---|
| MMC4 | Interleave | HTML | 4.0 | 122.5 |
| COYO | Img-text pair | Alt-text | 1 | 22.7 |
MMC4:Github已开源。论文包含了 585M 张图片和 43B 个英文单词,这些图片和文字相互交织,已经过滤了NSFW图像、广告等。它是对流行的纯文本c4语料库的扩充,其中包含了图像交错。mmc4涵盖了日常话题,如烹饪、旅行、技术等。
M3W (Multi Modal Massive Web):没开源,Flamingo使用的数据,是作者们从网页挖一些带有文本和图像的数据、视频、以及用了别人的文本和图像pair的数据,用185M图像和182G的文本,构成M3W数据集。

SparklesDialogue:Github已开源,一些强行构造的interleave数据,比如:观察img1和img2,他们在xx方面的区别是什么?
OBELICS:从HTML documents构建,已开源。
MINT-1T:已开源。BLIP3提出,包括the HTML subset, the PDF subset, and the ArXiv subset,比例是7:5:1。
3.图片sft数据
Idefics2:开源了1.88 M SFT数据 The_cauldron,多轮对话格式,是50个开源数据的合集。Idefics2的sft数据就是这个以及一些纯文本的数据的混合。
4.专项数据
OCR数据
王云鹤组整理,日常场景的那种OCR开源数据,来源是20个公开数据集,约5.6M真实的+17.9M仿真的:
https://github.com/large-ocr-model/large-ocr-model.github.io/blob/main/Data.md
SynthDoG datasets: Donut提出的数据集,用于增强ocr

The links to the SynthDoG-generated datasets are here:
synthdog-en: English, 0.5M.
synthdog-zh: Chinese, 0.5M.
synthdog-ja: Japanese, 0.5M.
synthdog-ko: Korean, 0.5M.
Docmatix:由hf开源,一个比DocVQA大百倍的QA数据集,pdf图片来自PDFA。
英文文档:https://huggingface.co/collections/pixparse/pdf-document-ocr-datasets-660701430b0346f97c4bc628
目前开源最好用的版面分析工具:https://github.com/opendatalab/PDF-Extract-Kit
手写体OCR:
中文:CASIA-HWDB2
英语:IAM
挪威语:NorHand-v3
视频数据
视频caption数据

粗加工
HowTo-100M(2019.6):HowTo100M 是一个大型叙述视频数据集,重点是教学视频,其中内容创建者教授复杂的任务,并明确解释屏幕上的视觉内容。 HowTo100M 共有以下功能:
- 1.36 亿个视频剪辑,其字幕来自 120 万个 YouTube 视频(15 年的视频)
- 烹饪、手工制作、个人护理、园艺或健身等领域的 23k 项活动
每个视频都配有一个旁白,可从 Youtube 自动下载字幕。

WebVid-10M(2021.4):论文 视频caption数据,一共有10M的video clip,还有个2.5M的子集。

HD-VILA-100M(2021.11):[CVPR 2022] 视频来源是youtube,用3.3M个视频切出了100M个视频片段,涵盖了YouTube上的15个最流行的视频类别,例如体育、音乐、汽车等。分辨率都为720p,平均时长为13.4秒。每个视频片段有一个对应的描述,但注意描述是根据ASR生成的,所以句子风格和我们理解的caption不太一样。每个句子平均包含32.5个词。
Panda-70M(2024.2):[CVPR 2024] 视频来源是youtube,70M个视频,每个视频由多个短caption和时间戳构成。
YouCook2 (2017):该数据集由涉及 89 个食谱的 2,000 个 YouTube 视频组成,均为未经剪辑的长视频,单个视频的平均长度为 5.26 分钟。全部采用第三人称视角。有动作描述、时间边界注释、目标的bbox。原始视频下载需要144G。
Charades (ECCV 2016):第一个家庭室内场景下的日常行为识别数据集,是通过众包完成的。数据集介绍见:https://blog.csdn.net/irving512/article/details/113473577
下载480p版本的视频需要13G。
Kinetics-400/710 (2017/19):deepmind提出。10s左右的人物动作视频,300k数据。简短的动作描述,包括人物的、人物和物体的、人物之间的。动作的类目包含了之前的数据、Motion capture(动作捕捉)任务以及人工收集整理。数据是youtube搜索到的。内容是人工标注的切片。在此基础上,又扩充到了700种,修缮了schema(合并删减、新的动作)
sthsthv2 (2017):把xx给xx;物理动作识别/描述的任务。主要是人物对某个对象进行某项操作,十分精细的数据。非常专业的数据,可惜目标比较少,相对而言还是会简单点。100k+问题,短视频短描述,人工标注,1000+人参与。
精加工
MiraData(2024.7):过滤最终有 9K data,过滤时采用帧率2 fps。MiraData是一个具有长持续时间(持续时间从1到2分钟不等)和 GPT-4V 打标的结构化caption(从不同的角度提供了详细的描述,平均caption长度为349个字)的大规模视频数据集。它是专门为长视频生成任务而设计的。目前MiraData包括两个场景:游戏、城市/风景探索。视频来源为在不同的场景中手动选择YouTube频道,并包括来自HD-VILA-100 M,Videovo,Pixabay和Pexels的视频。
它的数据构造流程挺好,提供了GPT4V prompt。788K 原数据在颜色过滤、美学质量、运动强度、NSFW四个过滤阶段后的数据量依次是:330K, 93K, 42K, and 9K video clips。

FineVideo(2024.9): 由HuggingFace开源。视频为从YouTube-Commons的190万英文视频中筛选的 43.7k 视频,筛选的既有视觉动作又有中快速语速的视频(通过词密度<0.5过滤和ffmpeg-Freezedetect视觉动态性过滤实现),视频时长小于10分钟。数据视频包括122个类别,它包含有关场景、人物、情节转折的多个短caption,有时间戳,有QA。官方提供了数据探索工具,点击链接可访问。数据构造的pipeline挺长的,可参考这篇博客 by HuggingFace Chinese in Bilibili
套餐数据

ShareGPTVideo(2024.4):Llava-Hound团队提出,共包括900k Detailed Video Caption,视频来自 400k WebVid + 450k Vidal + 50k ActivityNet。caption是对视频的详细描述。
"Although LLaVA-Hound contains the largest number of videos, 44% of its video data are sourced from WebVid, where most videos are static."
"LLaVA-Hound uniformly samples 10 frames from videos of any length. The average FPS is 0.008, which may miss some fine details."
——LLaVA-Video
ShareGPT-4o (2024.5):上海AI Lab提出。包含2k视频的caption。caption的风格是总分总结构,先简短总述,然后详细描述,最后简短说整体的氛围等。
ShareGPT4Video(2024.6):有 GPT4V 打标的40K 视频和他们训练的caption model打标的 4.8M 视频,视频来源包括Panda-70M、Ego4d、Pexels、pixabay、mixkit、BDD100K。视频时长从 2 秒到 2 分钟不等,平均26秒。提供有关键帧、时间戳、每个时间戳片段的caption、和这个视频的总caption,caption是GPT4V造的,caption在200-400词之间,平均273词,整体上是按照时间顺序在很详细的介绍视频内容。该数据存在的问题是使用非常稀疏的采样率进行帧注释。平均采样率为 0.15,有时仅从 30 秒的视频中采样 2 帧。
"ShareGPT4Video includes 30% of its videos from Pexels, Pixabay, and Mixkit, which are aesthetically good but also mostly static. Additionally, the majority of its videos come from Panda-70M, which are short clips from longer videos—suggesting simpler plots."
"ShareGPT4Video picks key frames using CLIP based on frame uniqueness. This method might also miss subtle changes in the video because CLIP embeddings do not capture fine-grained dynamics well."
——LLaVA-Video

视频sft数据
ShareGPTVideo-255k(2024.4): 240k QA+15k caption,是个大合集,包括了大多数的开源video sft数据。
Video-ChatGPT:10w 条开放式问答数据。VideoLLaVA、ShareGPT4Video 数据里都用了它,用法在 Github:VideoLLaVA,Github:ShareGPT4Video。
MVBench/Videochat2 的视频指令调整数据。
LLaVA-Video-178K (2024.10):包含178K个videos,长度0-3分钟。Video收集自youcook2 (2017), HD-VILA-100M (2022), sthsthv2 (2017), Activitynet (2015), kinetics (2017), charades (2016), Internvid-10M (2023), VidOR (2019), Ego4d (2022) 和 VIDAL (YouTube Shorts) (2023),涵盖了activities, cooking, TV shows, and egocentric views。视频都是选的动态的(如下图 ②通过PySceneDetect ④用于排除"slides." video);除了YouCook2和Kinetics-700,其他都用原始的、未修剪的视频来确保情节的完整性。标注包括 178K capton,960K open-ended QA,196K MC QA,共 1.3M,标注基于1fps采样,由GPT-4o和人工校验得到。QA包括16 question types。
链接中的数据为论文LLaVA-Video使用的 video 数据,除了LLaVA-Video-178K,还包括了 ActivityNet-QA、NExT-QA、PerceptionTest 和 LLaVAHound-255K,所以一共是 1.6M。which include 193,510 video descriptions, 1,241,412 open-ended questions, and 215,625 multiple-choice questions. Remarkably, 92.2% of the video descriptions, 77.4% of the openended questions, and 90.9% of the multiple-choice questions were newly annotated.(LLaVA-Video还使用了1.1M的 image-language pairs from the LLaVA-OneVision。)





推荐下我们自己的 benchmark 和数据:
针对抽象图等任务场景专门生成的 benchmark, 例如图表,流程图,组织架构图,导航地图,仪器表盘图,网页布局,建筑布局等抽象图
Multimodal Self-Instruct: Synthetic Abstract Image and Visual Reasoning Instruction Using Language Model
👍