🎯 VLM常用的Benchmark
本文对多模态大模型中多个视频和图文任务的常见benchmark做了简要介绍,以方便读友看论文时参考。
可参考使用的评测框架有 OpenCompass 提出的 VLMEvalKit 和 llava团队提出的 lmms-eval。
注意:本文信息仍在时常更新中...
视频多模常见任务和评测数据
视频QA中有的是主观题有的是客观题,即开放式问答和选择题两种,开放式问答的评测需要GPT API或者部署开源大模型用来评测。选择题可以直接评测。


选择题型
- VideoMME (2024.5):一堆高校提出。涵盖了 6 个主要视觉领域和 30 个子领域(见下左图),共900 段视频,2,700 个问题-答案对,除了视频帧之外,还整合了字幕和音频等多模态输入。评测分短(0~2min)、中(4~15min)、长(30~60min)三种时长的视频,每种还分有无字幕的结果。所有数据都是由人类新收集和注释的,而不是来自任何现有的视频数据集。测试时,短中视频 1fps,长视频长度少于 384 秒的,以 1fps 采样,对于超过 384 秒的视频,均匀提取 384 帧。

- MVBench (2023.11,上海AI lab):VideoChat2提出的,侧重于评测视频中事件和行为识别(temporal tasks)的能力。提供VideoChat2的sft数据。视频全部来自 STAR、CLEVRER、PAXION、TVQA等开源视频。20个任务如下图,每个任务200条问答,共4000条QA。

- TempCompass (ACL 2024 Findings):由北大提出,主要评测模型对于时序关系和事件发展等能力(temporal tasks)。会把视频反向播放来提问速度和事件顺序,以防止模型利用单帧偏差和语言先验。multi-choice QA有1.58k,yes/no QA有2.45k,caption_matching有1.5k。数据预览

- VideoVista (2024.6):包含了来自 14 个类别(例如,Howto、电影和娱乐)的 3400 个视频的 25000 个问题,视频时长从几秒到超过 10 分钟不等(但多数在3分钟内)。问题分了视频理解和视频推理两大类,涵盖了包括grounding、异常检测、交互理解、逻辑推理和因果推理在内的各种task,需要模型有目标检测能力。目前VLM比较薄弱的包括:temporal location, object tracking, and anomaly detection。
14个视频类别:Howto & Style(H&S),新闻与政治(N&P),宠物与动物(P&A),汽车与车辆(A&E),游戏(Gam.),电影与动画(F&A),体育(Spo.),娱乐(ENT.),人物与博客(P&B),旅游与活动(T&E),喜剧(Com.),科学与技术(S&T),教育(Edu.),音乐(Mus.)

-
LongVideoBench (2024.7):NTU & Salesforce blip团队。包含 3763 个从网络收集的不同长度的视频,以及它们的字幕,覆盖了多种主题。6678个问题-答案对。LongVideoBench突出长帧推理能力,问题不能很好地被单帧或少数稀疏帧处理。榜单中GPT和Gemini遥遥领先,开源的各种视频VLMs和图片VLMs差距都不大。问题风格偏细节,比如视频中某个人的背包的变化,适合根据提问先索引,然后推理回答。
-
EgoSchema (2023.8): UC Berkeley提出。视频 clips 为3分钟,源自Ego4D,由第一人称视角的广角镜头拍摄。Benchmark 由5000多个人工构造的选择题 QA 组成,涵盖了250多个小时的真实视频数据,涵盖了非常广泛的自然人类活动和行为。问题里面的people都用C或c代替。题目很难,侧重于推理,人类正确率76%,7B 模型正确率低于35%。问题风格适合看完整个video,然后进行回答。
-
NExT-QA (CVPR2021): NUS提出。也有开放式问答的版本NExT-OE。NExT-QA 总共包含 5440 个视频,平均长度为 44 秒,视频主要展示了日常生活中的物体互动。尽管没有限制视频内容,但它们大多涉及家庭时光、孩子玩耍、社交聚会、体育活动、宠物和音乐表演。大约有 5.2 万个手动标注的问答对,被分组为因果(48%)、时间(29%)和描述(23%)问题。特别为每个视频标注大约 10 个问题,涵盖不同种类的内容。数据集视频分为训练/验证/测试:3870/570/1000,QA数量为训练/验证/测试:34,132/4,996/8,564。
开放式问题型
- MLVU:MLVU: Multi-task Long Video Understanding Benchmark 长video理解。lmms-eval代码已集成。既有选择题,也有主观题,分布如下图。

- ActivityNetQA (2019.6):由来自 ActivityNet 数据集的 5800 个视频中的 58000 个人工标注的问题-答案对组成,其中测试集8,000 QA pairs on 800 videos。关注长期空间-时间推理能力。属于开放式问答,但是问题答案都很简短,由一个单词或一个短语构成,也包含很多Yes/No问题,所以用规则式评测也可以。
- VCGBench:只用了ActivityNet200 数据集中的视频,包含了 500 个视频和 3000 个问答对。
- VCGBench-Diverse (2024.6):共包含 877 个视频、18 个广泛的视频类别和 4,354 个 QA 对。视频来自 HDVILA、MPII、YouCook2、UCF Crime 和 STUD Traffic 等。都是主观题,一句话形式,必须用LLM评测。

- MMBench-Video: 上海AI Lab提出,视频最长6分钟,平均165.4秒,包括 16 个主要类别的 609 个视频片段,共1,998 个QA。QA都是主观题,答案有长有短,平均8.4 words,需要用LLM评测。所有分数均基于 3 级评分方案:0 表示最差,3 表示最好。

- [Visual Needle-In-A-Haystack (V-NIAH)]():LongVA提出
图文多模常见任务和评测数据
常见的多模态任务有:视觉问答VQA、视觉常识推理VCR(选择题并解释原因)、指代表达RE(给定图片和一个句子,判断句子正确还是错误)、图文检索VLR(根据文字检索图片)。生成图片类任务有:图像样式转移、文本驱动的图像生成等。
不同任务常用benchmark如下:
VLM 综合评测 benchmark:
OpenCompass 和 OpenVLM 包括了大多数的综合榜单。包括但不限于:
- MM-Vet:只有英文,包括6种能力纬度:Recognize、OCR、Knowledge、Generate、Spatial、Math。
- MMBench:(有中英文赛道,选择题)大约 3000 个问题,涵盖了 20 个L3级别的能力维度。每个问题都是单选题格式。使用圆周评价策略,将选择和相应的答案进行循环移位,推理N次,只有都对才算对。MMBench is collected from multiple sources, including public datasets and Internet, and currently, contains 2974 multiple-choice questions, covering 20 ability dimensions. We structure the existing 20 ability dimensions into 3 ability dimension levels, from L-1 to L-3. we incorporate Perception and Reasoning as our top-level ability dimensions in our ability taxonomy, referred to as L-1 ability dimension. For L-2 abilities, we derive: 1. Coarse Perception, 2. Fine-grained Single-instance Perception, 3. Fine-grained Cross-instance Perception from L-1 Perception; and 1. Attribute Reasoning, 2. Relation Reasoning, 3. Logic Reasoning from L-1 Reasoning. To make our benchmark as fine-grained as possible to produce informative feedbacks for developing multi-modality models. We further derive L-3 ability dimensions from L-2 ones.
- MME(2023.6,腾讯优图):测试Yes/No问题回答能力,the full scores of perception and cognition are 2000 and 800, respectively. 总分是2800。

- MMStar(集成数据集,包含了seed、mmmu、AI2D、math-vista等)
- SEED
- MMMU,CMMMU:选择题+少量开放题,需要知识,需要大LLM
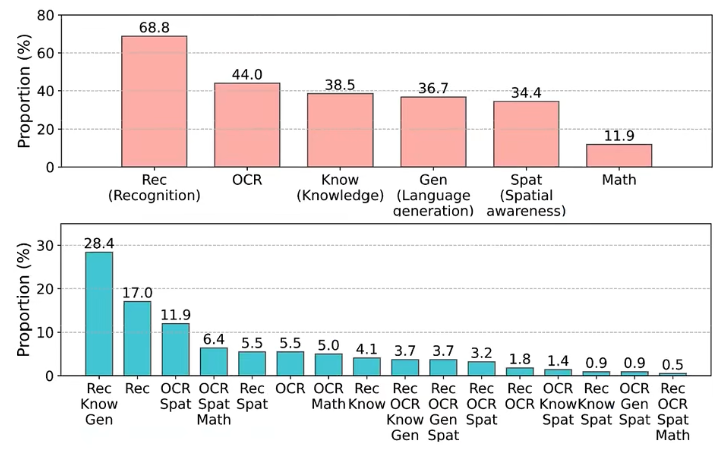
其中MM-Vet归纳了VLM需要具备的6种能力,并组合出16种任务,比例如下:
幻觉
- POPE(人大):YES/NO题,造了一些高频共现的目标,然后问图片中是否有某object,看模型幻觉
- Object HalBench
$$\text{CHAIR}_{I} = \frac{\lvert \{\text{hallucinated objects}\} \rvert}{\lvert \{\text{all mentioned objects}\} \rvert}, \text{CHAIR}_{S} = \frac{\lvert \{\text{captions with hallucinated objects}\} \rvert}{\lvert \{\text{all captions}\} \rvert}$$ - MHuman Eval
- Hallucination frequency
- MMHal-Bench
- Info: GPT-4 evaluated score
- Hallucination frequency
Image Caption
- COCO
- MM-IT-Cap
Visual Question Answering(VQA)

- VQAv2(自然场景,1~2个单词的QA):train 444k, validation 214k,testdev 107k, test 448k。数据集可视化,没有benchmark主页,参考性能为:Idefics2-8B(320tokens/image)81.2
- VizWiz
- GQA (自然场景图问答,有框标注)
- Hateful Meme
- PointQA(ChatSpot)
- COCO Text(ChatSpot)
- OKVQA(特别是用于测试 external knowledge)
- TextVQA(涉及OCR能力):需要结合场景+文字的QA。对vision encoder的输入分辨率敏感。
图片来源 OpenImages v3
训练集:21,953 张图像,34,602 个问题,验证集: 3,166 张图像, 5,000 个问题
测试集: 3,289 张图像, 5,734 个问题 - STVQA
数据来源 :Coco-Text, Visal Genome, VizWiz, ICDAR(13+15), ImageNet, IIIT-STR
训练集:19,027张图像,26,308个问题
测试集: 2,993 张图像, 4,163个问题 - DocVQA
- OCR-VQA
207572 张图像(书的封面),超过100万个问答对 ( train : val : test = 8 : 1 : 1 )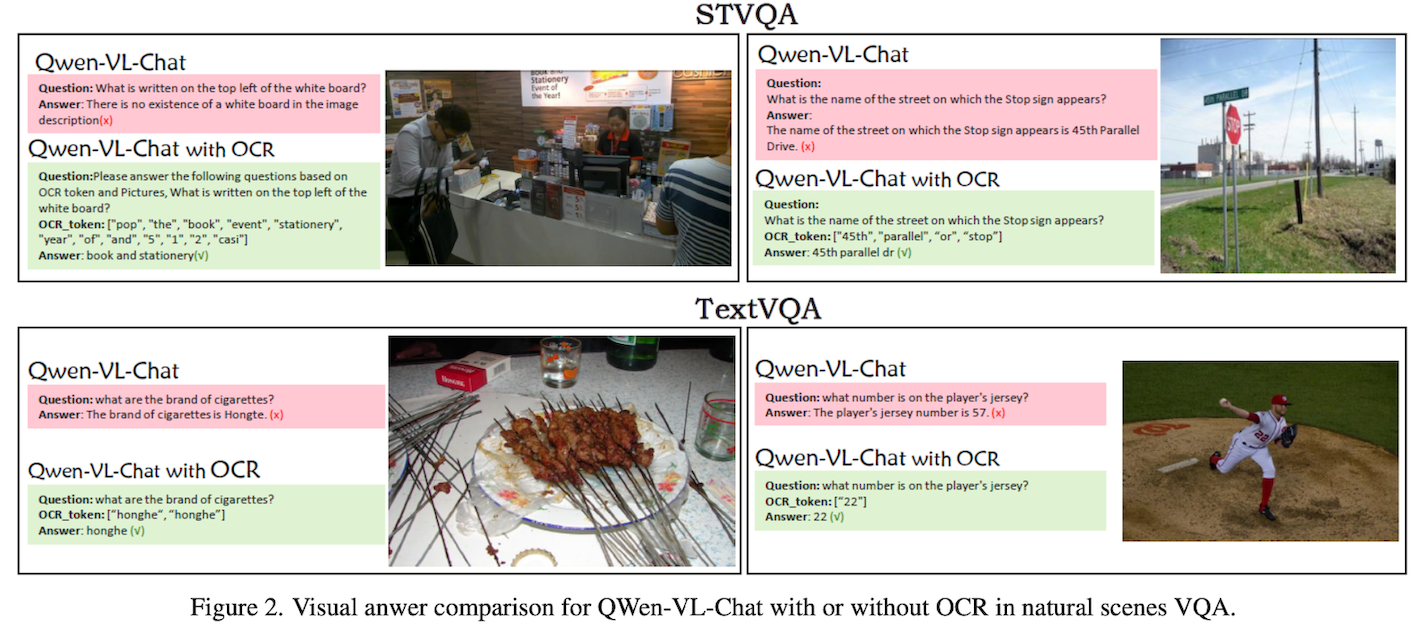

- OCR-Becnch:文字识别、场景文字理解、文档问答、关键信息抽取相关的开放问题。存在泄题,上800得刷他那些数据集。
- ChartQA:test有1509张图
- PlotQA:test有33657张图
- DVQA
Visual Grounding/REC
- Flickr30k(短语定位)
- RefCOCO、
- RefCOCO+、
- RefCOCOg:
是三个从MSCOCO中选取图像和参考对象的Visual Grounding数据集。目标属于80个目标类。
RefCOCO有19,994幅图像,包含142,210个引用表达式,包含50,000个对象实例。
RefCOCO+共有19,992幅图像,包含49,856个对象实例的141,564个引用表达式。
RefCOCOg有25,799幅图像,指称表达式95,010个,对象实例49,822个。
在RefCOCO和RefCOCO+上,遵循train / val / test A / test B的拆分,testA中的图像包含多人,testB中的图像包含所有其他对象。RefCOCOg遵循train / val / test 的拆分。
RefCOCO的表达式分别为120,624 / 10,834 / 5,657 / 5,095; 框的数量分别为42,404 / 3,811 / 1,975 / 1,810
RefCOCO+的表达式分别为120,191 / 10,758 / 5,726 / 4,889; 框的数量分别为42,278 / 3,805 / 1,975 / 1,798
RefCOCOg的表达式分别为80,512 / 4,896 / 9,602; 框的数量分别为42,226 / 2,573 / 5,023
RefCOCO的查询包括方位或属性,如“中间的人”,“左边 红衣服”,“蓝车”;RefCOCO+的查询不包含方位,如“手里拿着球拍”;RefCOCOg的查询长度普遍大于RefCOCO和RefCOCO+:RefCOCO、RefCOCO+、RefCOCOg的平均长度分别为3.61、3.53、8.43。
RES
- PhraseCut
- RefCOCO
Detection
- COCO,train和val有标注
COCO2014: train包括 82783张图,val包括 40504张图,test包括40775张图
COCO2017: train包括 118287张图,val包括 5000张图,test包括 40670张图 - Object365
- OpenImage

