📄 OneChart—让VLM知之为知之,不知为不知
论文:OneChart: Purify the Chart Structural Extraction via One Auxiliary Token
主页及demo:https://onechartt.github.io/
《论语》中说:“知之为知之,不知为不知,是知也”。从神经网络兴起以来,人们就没有停止过对这种黑盒模型应用在生产环境的担心。在AI 1.0中大部分模型还至少会输出一个置信度得分可供参考;然而对于AI2.0时代的VLMs来说,所有的结果以文本的形式吐出,这加重了人们对模型安全性的焦虑。让模型知道自己的能力边界,不要产生致命错误,这点十分必要,也是目前的难点。
图表(柱状图,折线图,饼图)的信息结构化提取(SE)是对模型可靠性要求极高的任务之一,同时也是VLM难解的问题之一。经测试,即使是GPT4V对于chart也常常不能正确理解,特别是chart中的数值不能通过调用OCR简单获取的时候。
为此所提出的OneChart选取图表SE这一任务,展示了一种简单有效的方法。仅通过一个辅助token和对应的辅助decoder设计,不仅增强了模型的特定能力,还能在推理时对模型的文本输出给出一个可靠性检查。文章所提的OneChart参数量仅0.2B,但在SE任务中可以大幅领先目前的1.3B~13B模型。OneChart还可以作为一种Chart-Agent来帮助现有的LLM或VLM更好的完成下游QA任务,例如LLaVA1.6+OneChart可以在ChartQA数据集上涨点 11.2。
任务和方法介绍
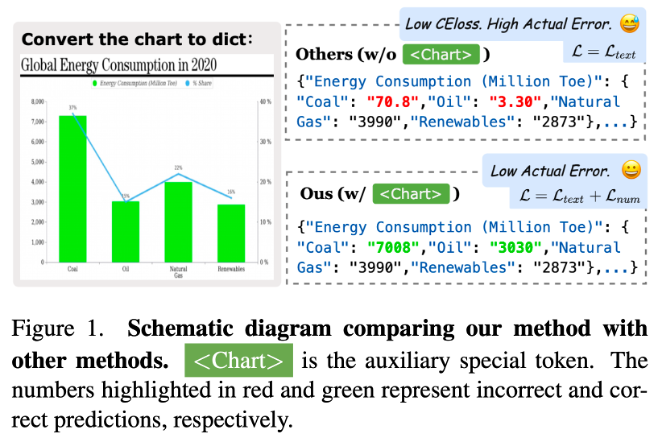
Chart理解和推理能力是目前VLM研究中的重点之一。作者认为目前用VLM进行 Chart解析有两部分需要改进:一是需要充分训练一个真正会看chart的vision encoder;二是在SE任务中单纯对文本输出算交叉熵损失不是最优的,比如当gt是7008时,模型输出70.8和7007损失是一样的,但显然7007是相对可以接受的误差,特别是当chart图片中没有明确的数值标注的时候。如图1,Onechart的做法是引入了一个辅助decoder,并设计L1 loss来进行监督。
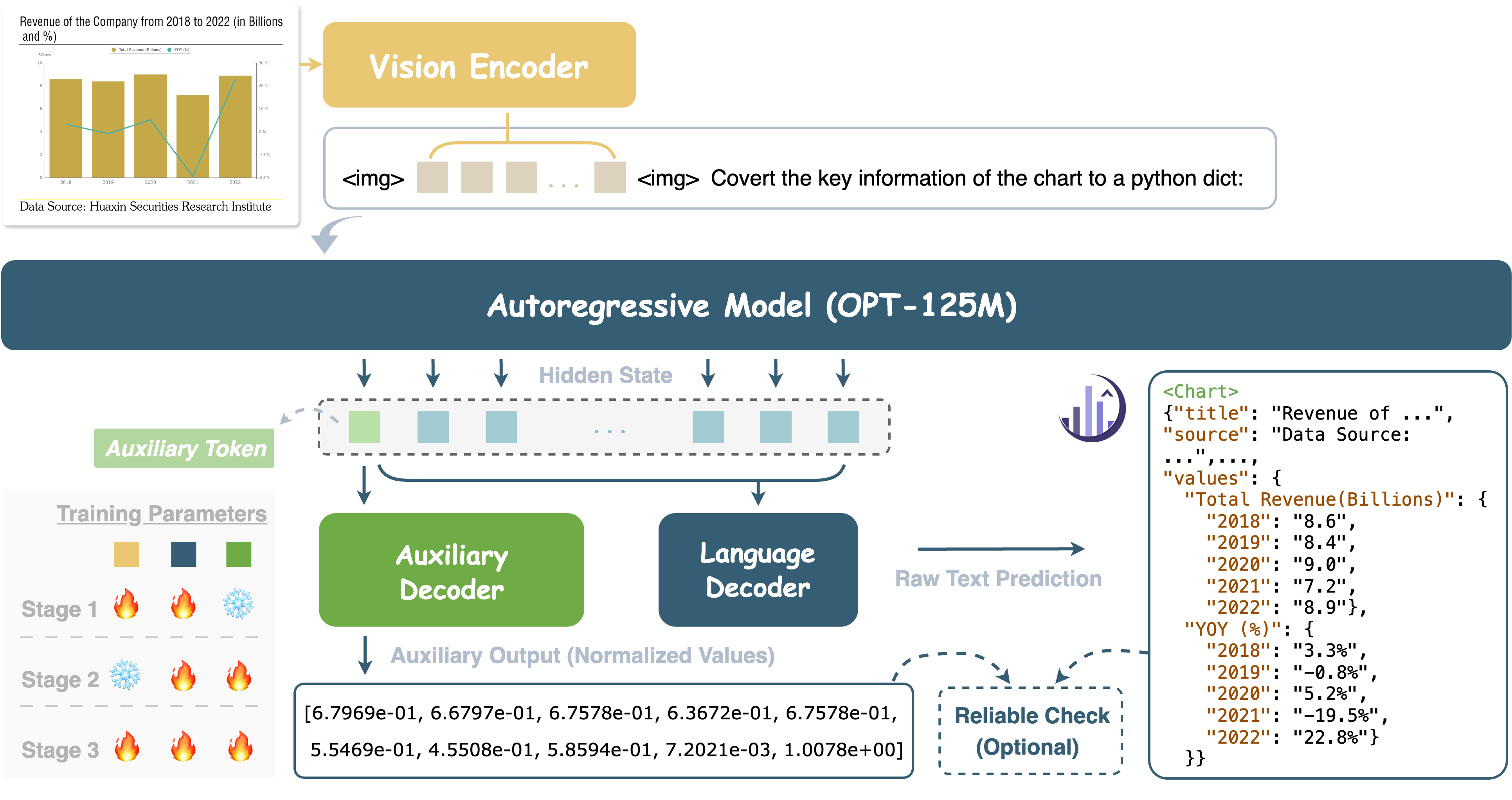
OneChart的模型结构如下图,主要包括vision encoder、OPT-125M、Auxiliary decoder三部分。Auxiliary decoder由3层MLP组成,以 Auxiliary token
当然,在推理时也可以选择不丢弃辅助decoder,而是用辅助decoder输出的结果和语言模型输出的结果进行可靠性校验:将语言模型输出结果中的数值min-max归一化后,与辅助decoder输出的结果计算L1距离。通过设置阈值判断模型输出的可靠性。更多的技术细节,请查看OneChart的论文。
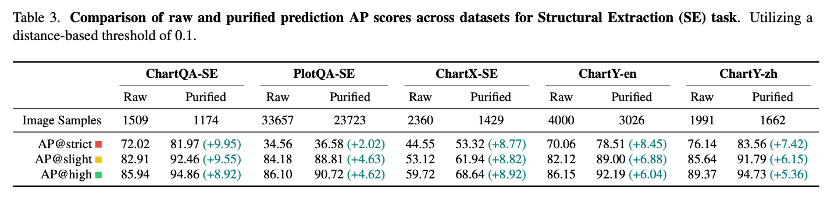
性能展示
OneChart提取图表信息的量化性能得分如下,其中Structural Extraction任务衡量的是模型提取chart主体部分entity和对应数值的准确性。可以看到OneChart的AP@strict显著优于其他模型,整体性能也是SOTA水平。
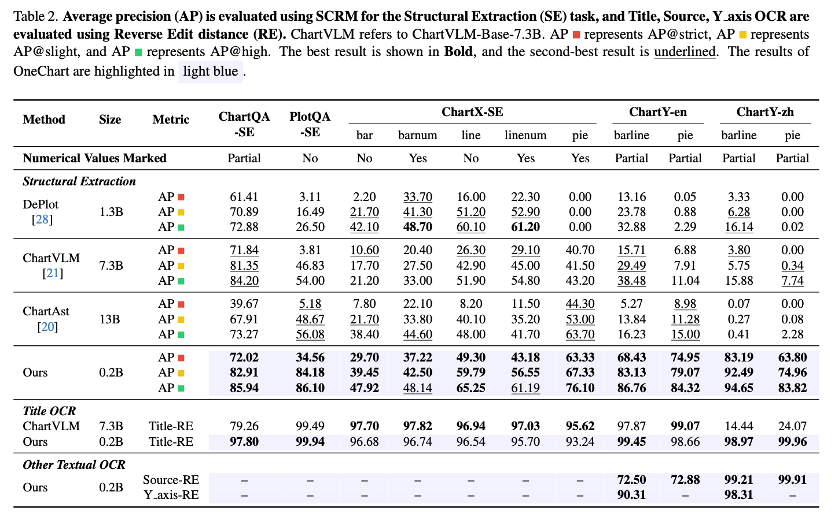
下面这个表格展示的是推理时采用可靠性校验筛选出的purified预测和原始所有预测的性能AP对比。可以看出可靠性校验的筛选能力是显著的。